なぜテストを受けるのですか?
ほとんどの癌では、早期発見は生と死の違いを意味します。

ニューイングランドジャーナルオブメディシンに掲載された画期的な研究によると、肺がん(世界一のがんキラー)では、がんがまだ小さく閉じ込められた状態(ステージ1)でスクリーニングによって検出された場合、生存率は90%を超えます。一方、米国癌協会のWebサイトによると、肺がんが進行して複数の遠隔腫瘍(ステージIVb)を形成すると、生存率は1%未満に低下します。何十もの同様の研究は、膵臓、結腸、腎臓、卵巣、および他のほとんどの腫瘍タイプについて、早期発見が実質的な生存利益を提供すると結論付けています。OneKensaの一部として測定されたバイオマーカー (AFP、CEA、PSA、CA 19-9、CA 125、CA 15-3、およびCYFRA 21-1)は、さまざまな悪性腫瘍の存在と有意に関連しており、早期のより治癒可能な段階で癌を検出する可能性があります。患者はまだ無症候性です。
誰が利益を得る可能性がありますか?

ほとんどの人は、家族歴、ライフスタイル、および環境曝露が癌の主な原因であると誤って想定しています。しかし、ジョンズホプキンスの主要な癌遺伝学者による2017年の報告された研究では、すべての腫瘍タイプの中で、癌につながる遺伝子突然変異の66%が生涯にわたるランダムな突然変異に由来し、29%がライフスタイルまたは環境に由来し、わずか5%が親から受け継いだ遺伝子。
したがって、がんの家族歴がほとんどないかまったくなく、健康的なライフスタイルを送っている人でも、定期的にがんの検査を行うのが賢明です。これは、日本、韓国、中国、および極東全域での標準的な慣行であり、約40歳から始まるほぼすべての成人が、「通常、一部である同じタンパク質バイオマーカーの多くの血液検査を含む、終日の健康診断を実施します。
どのくらいの頻度でテストする必要がありますか?

時間の経過に伴うバイオマーカーレベルの増加は、単一の時点の測定値よりも癌のより良い予測因子であることが実証されているため、バイオマーカーの癌スクリーニングが一般的である地域の多くの専門家は、毎年の検査が早期発見率を改善するための最適な方法であると信じています。さらに、OneKensaのお客様の1年間の結果を監視しているため、機械学習アルゴリズムを長期的な結果データで変更すると、機械学習アルゴリズムがますます強力で正確になり、毎年の再テストを行う人にさらなるメリットがもたらされると予想されます。
それはどのように機能しますか?

OneKensaのユニークな機能は、機械学習アルゴリズムを組み込んで、バイオマーカーテストのみのパフォーマンスを向上させることです。機械学習は人工知能(AI)の一種であり、コンピューターシステムは新しいデータを継続的に処理して組み込み、時間の経過とともにその出力を微調整することができます。バイオマーカーレベルと関連する臨床因子データを組み合わせるために使用されるアルゴリズムは機械学習から派生しているため、このアルゴリズムは定期的なレビューと再定義に適しています。米国の人口からの追加データを活用し、臨床因子予測因子の数を増やすことで、時間の経過とともにOneKensaアルゴリズムの精度を向上させます。
バイオマーカーレベル、臨床入力、および癌/非癌の結果をさらなるアルゴリズム開発に使用することを許可するOneKensaのお客様は、最終的には、その後テストを受ける人々の健康上の結果を改善するのに役立ちます。
OneKensaのユニークで有利な点は何ですか?
これは、米国では広くスクリーニングされていない肺、肝臓、膵臓、およびその他の癌の早期発見に役立ちます。
極東では、すべての主要ながんの種類のスクリーニングが数十年にわたって行われていますが、ほとんどのアメリカ人は、結腸がんに加えて、女性の乳がんと子宮頸がん、男性の前立腺がんについてのみ定期的に検査されています。OneKensaは、肺、肝臓、膵臓、卵巣、腎臓などのさまざまな種類の癌を同時にスクリーニングする、米国で利用可能な最初の血液検査の1つです。
私たちは、将来ではなく、現在の早期癌の検出に役立つ腫瘍タンパク質(遺伝子ではない)を測定します。
今日、多くの人気のあるDNA検査会社は、祖先分析だけでなく、消費者をさまざまな病気にかかりやすくする遺伝性遺伝子異常の検査も提供しています。最近の研究では、癌を引き起こす遺伝子変異の5%未満が遺伝性であることが確認されているため、このような検査は癌の早期発見に非常に限られた価値しかありません。代わりに、ほとんどの癌の原因となる突然変異は、時間の経過に伴うランダムなDNAコピーエラーに起因します。
遺伝性の遺伝子変異を超えて、血液中の循環腫瘍DNA(「ctDNA」)が癌の早期発見に役立つかどうかを研究するための研究が多くの人によって進行中です。ctDNAバイオマーカーが相補的であるか、タンパク質バイオマーカーよりも優れているかを判断できるようになるまでには、おそらく数年かかるでしょう。20/20とその研究協力者は、循環腫瘍DNAの将来の可能性を検討し、まさにこの目的のために、できるだけ多くのお客様から過剰な血液サンプルを収集して保存することを計画しています。
私たちのアルゴリズムはすでにより良い精度を提供しており、時間の経過とともに継続的に改善されることが期待されています。
機械学習を使用して、バイオマーカーレベルや、年齢や性別などの他の特性を、過去12年間にテストされた28,000人の被験者の膨大なデータベースと比較します。このアプローチは、バイオマーカーテストのみの場合のほぼ2倍の数の癌を検出するのに役立つことが実証されています。(詳細については、精度、信頼性、科学的サポートを参照してください。)現在のアルゴリズムは、これまでに実施された厳密な調査に基づいて修正されていますが、20/20 GeneSystems、Inc。は、既存のアルゴリズムの定期的なレビューの実行に取り組んでいます。ドライバーのコミュニティがリアルタイムの道路情報を共有して他のドライバーに交通と道路の状態を警告する人気のある交通とナビゲーションのアプリと同様に、OneKensaユーザーはバイオマーカーレベル、臨床入力、
OneKensaは、無症候性の個人からの実際のデータによって強化および検証されています。
ほとんどのバイオマーカーベースの癌検査は、癌患者からの保存された実験室血液サンプルを使用して開発および検証されています。これらの検査の精度は、通常、後で実際のスクリーニング環境で使用されると大幅に低下します(つまり、癌の兆候や症状のない個人)。
OneKensaは、台湾の主要な研究病院で12年間にわたってスクリーニングされた約28,000人の個人からの1年間の結果データに基づいて開発および検証されました。このデータセットは成長し、アメリカの消費者からの結果を統合します。
精度、信頼性、科学的サポート
この種の臨床検査の精度は、一般に、次のようないくつかの個別の指標によって特徴付けられます。
- 「感度」(適切に分類された真のがんの割合)および、
- 「特異性」(適切に分類された真の非がんの割合)。
したがって、テストの感度が高いほど、見逃される癌は少なくなります。テストの特異性が高いほど、誤検出の結果は少なくなります。
これらの概念は、このビデオで説明されています。バイオマーカーのみの精度。さまざまな癌に対するOneKensaTMのバイオマーカーの性能を単独または組み合わせて評価する科学的および医学的文献には何百もの報告があります。15年間で41,516人以上の研究参加者が参加した実際のスクリーニング設定(すなわち、癌の診断前の個人の検査)からのこれらのバイオマーカーの
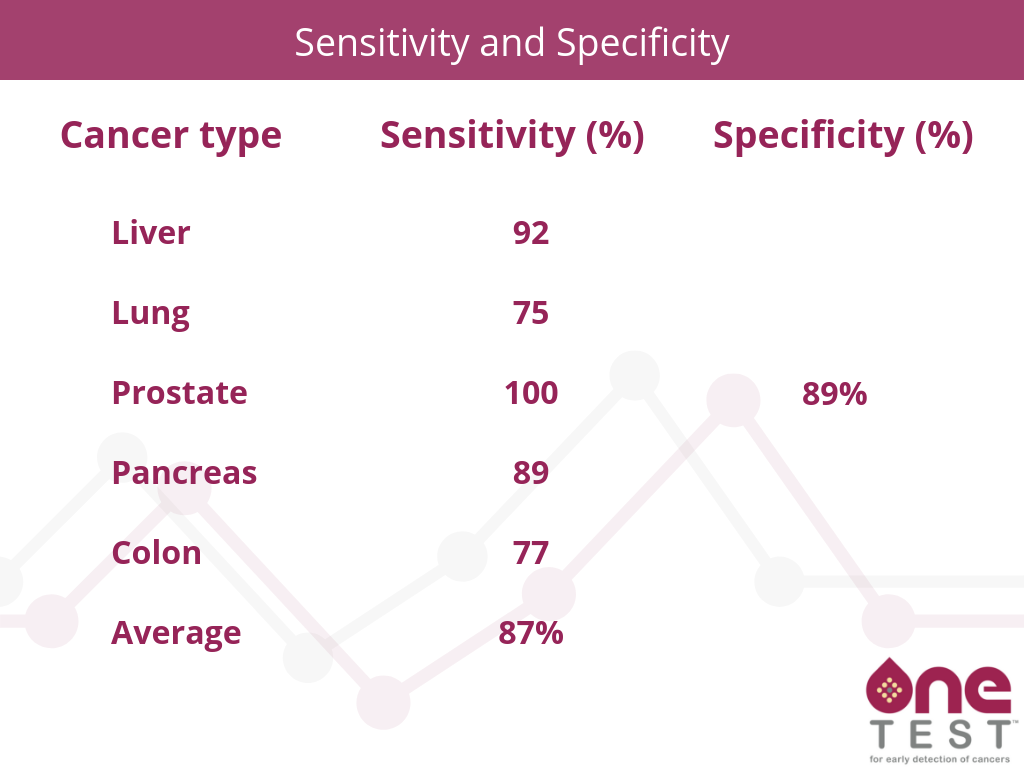
おそらく最も包括的な研究(2015年に公開)では、のバイオマーカーのパネルOneKensaTM(しきい値を超えるパネル内の任意の1つのマーカーに基づく、アルゴリズムなし)88.7%の特異性で、肝臓がん、肺がん、前立腺がん、および結腸直腸がんの検出感度は90.9%、75.0%、100%、および76.9でした。 % それぞれ。バイオマーカーにより、以下の感度が見られました(88.7%の特異性):
表1 *。各悪性腫瘍に対する個々の腫瘍マーカーの感度。
| 悪性腫瘍の種類 |
PSA |
AFP |
CEA |
CA19-9 |
CYFRA 21-1 |
CA 125 |
SCC |
CA15-3 |
Panel |
||
| 前立腺がん |
100 |
0 |
0 |
4.8 |
5.9 |
– |
5.6 |
– |
100 |
||
| 肝細胞癌 |
13.3 |
63.3 |
5.6 |
31.6 |
10 |
0 |
0 |
0 |
92.3 |
||
| 膵臓癌 |
0 |
0 |
55.6 |
62.5 |
33.3 |
66.7 |
0 |
0 |
88.9 |
||
| 結腸直腸がん |
7.1 |
5.9 |
53.8 |
25 |
38.9 |
22.2 |
5.9 |
12.5 |
76.9 |
||
| 肺癌 |
9.1 |
5.7 |
72.2 |
12.9 |
40.9 |
20.0 |
8.7 |
20.0 |
75.0 |
||
| 膀胱がん |
25 |
0 |
33.3 |
69.2 |
57.1 |
50.0 |
60.0 |
0 |
64.3 |
||
| 子宮頸癌 |
– |
7.1 |
20.8 |
5 |
11.1 |
30.4 |
20.8 |
0 |
44.4 |
||
| 胃癌 |
0 |
6.3 |
25 |
6.7 |
41.7 |
0 |
9.1 |
0 |
38.9 |
||
| 乳癌 |
– |
5.4 |
8.1 |
9.7 |
11.1 |
20.5 |
3.1 |
5.4 |
37.5 |
||
| 卵巣がん |
– |
0 |
0 |
50 |
0 |
0 |
0 |
0 |
33.3 |
||
| 口腔がん |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
||
| 特に明記されていない限り、データはパーセンテージで示されます。 | |||||||||||
| 略語:PSA、前立腺特異抗原; AFP、α-フェトプロテイン; CEA、癌胎児性抗原; CA、癌抗原; | |||||||||||
| CYFRA、サイトケラチンフラグメント; SCC、扁平上皮細胞特異的抗原 | |||||||||||
| 口腔がんには、舌、口腔、中咽頭に発生する悪性腫瘍が含まれていました | |||||||||||
このドキュメントの他の場所で指摘されているように、順次テストと単一の時点の測定値を比較することが、これらのバイオマーカーの価値を最大化するための最良の方法です。つまり、さまざまなバイオマーカーのレベルの経時変化は、癌の出現と進行を予測するための最も価値のある情報を提供することが期待されます。アルゴリズムの精度。台湾の協力者と協力して、臨床的要因(年齢、性別など)をバイオマーカーレベルと統合する機械学習アルゴリズムが、バイオマーカーレベルのみよりも精度を大幅に向上させるという説得力のある証拠を生成しました。

- バイオマーカー測定のみを使用したすべての癌(優れたバイオマーカーが不足している皮膚癌など)のパフォーマンスでは、89%の特異性で57%の感度が得られました。OneKensaのアルゴリズムは、これらの結果を男性で82%の感度と80%の特異性に改善しました(ステージ4を除く)。
- 肝臓、肺、結腸直腸、または前立腺のいずれかのがんの種類(ステージ4を除く)の男性を対象とした、東アジアの2番目の国の個人による独立した研究に基づくと、この検査の感度は、約80%。肺がん、肝臓がん、または結腸直腸がん(ステージ4を除く)の女性の場合、検査の精度は低くなります
注意事項:これらのアルゴリズムは、台湾の人口からのデータを使用して構築されました。米国の人口から生成された十分なデータが取得されるまで、米国の人口に対するそれらの精度を予測することはできません。機械学習アルゴリズムは、アメリカ人とアジア人の両方の母集団、特に毎年このテストを受ける個人からの追加データ(多くの臨床的要因を含む)が組み込まれるため、時間の経過とともに精度が大幅に向上することが期待されます。2018年半ばの時点で、OneKensaバイオマーカーは、以前に診断された患者の再発がんの検出に使用するためにFDAが承認したRocheIVDバイオマーカー検出キットを備えたRocheCobase411イムノアッセイアナライザーを使用してアッセイされます。追加の技術的および科学的詳細が見つかる場合がありますここ。
テストの長所と制限の要約

- データは、診断の1年前までに検査された癌患者を対象とした実際のスクリーニングセンターから生成されました。
- OneKensaの開発のために調査された集団は、健康診断センターを訪れた一般的に健康な集団でした。この現実世界の人口は、すでに癌と診断された後にコホートを調べる「ケースコントロール」研究よりも高い精度を提供する可能性があります。
- 大規模なデータセット(40,000以上)がOneKensaの基礎でした。
- OneKensaで採用されているBiomarkerテストキットとアナライザーは、世界中の何千もの臨床ラボで日常的に使用されており、毎年何百万もの個人をスクリーニングしています(Roche Cobas Analyzer andReagents)。
- OneKensaアルゴリズムは、人工知能(AI)の一種である機械学習を使用します。この学習では、コンピューターシステムが新しいデータを継続的に処理および組み込み、時間の経過とともに精度を向上させることができます。
- 患者のバイオマーカーレベルを関連する臨床因子データと組み合わせて解釈するために使用されるアルゴリズムは機械学習から派生しているため、このアルゴリズムは定期的なレビューと再定義に適しています。
- 現在のアルゴリズムはこれまでに実施された厳密な研究に基づいて修正されていますが、20/20 GeneSystems、Inc。は、既存の患者データセットの拡大に合わせてアルゴリズムの定期的なレビューを実施することをお約束します。
- OneKensaに続く患者のフォローアップからの結果データを提供することにより、実際の経験はOneKensaアルゴリズムのさらなる開発と微調整に情報を提供し、テストの精度を継続的に向上させることができます。
- 私たちのデータベースは、信頼できる結果データが収集されるにつれて、テストが米国全体および他の場所で使用されるにつれて、量および地理的/民族的多様性が増大します。したがって、私たちのアルゴリズムは継続的に学習し、改善することが期待されています。
制限事項
- これは癌の決定的な検査ではありません。癌の唯一の決定的な検査は、資格のある病理医による生検組織の分析です。
- OneKensaは、がんの存在を確認するためのさらなるフォローアップテストの潜在的な必要性を示すための初期画面として意図されています。OneKensaで癌の可能性が高いが、癌ではない可能性があります。低いOneKensaスコアの結果は、癌の存在を除外するために使用されるべきではありません。
- 東アジアのデータから導出されたアルゴリズムは、アメリカの人口に正確に変換されない場合があります。
- 個々の腫瘍マーカーの高得点(偽陽性)は、癌ではない良性の状態に起因する可能性があります。
- 人が低いスコアを受け取ったが、癌を持っている可能性がある場合、偽陰性の結果になります。
- 現在、女性の精度は男性ほど高くありません。おそらく、OneKensaの1つまたは複数のバイオマーカーの上昇に寄与する月経期間の制御の失敗が原因です。

OneKensaのアカデミックサポートを表示する
機械学習アルゴリズム により、複数の癌を早期に検出するための多腫瘍バイオマーカーパネルの精度が大幅に向上します